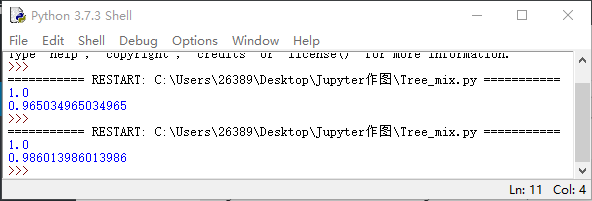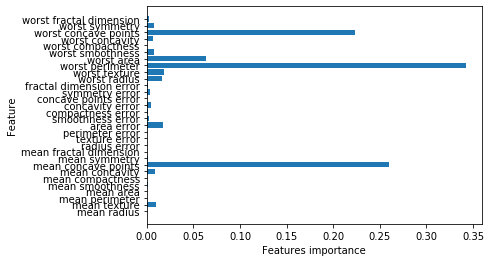
尝试了一波单一决策树模型和集成决策树,也体会了一波大量数据训练和增加迭代次数对模型的影响,100,0000棵树了解一下🤣
!/usr/bin/env python
coding: utf-8
In[1]:
from sklearn.model_selection import train_test_split
In[2]:
from sklearn.ensemble import GradientBoostingClassifier
In[3]:
from sklearn.datasets import load_breast_cancer
In[4]:
import matplotlib.pyplot as plt
In[5]:
import numpy as np
In[6]:
cancer = load_breast_cancer()
In[7]:
X_train,X_test,y_train,y_test = train_test_split(cancer.data,cancer.target,random_state = 0)
In[8]:
'''
grbt = GradientBoostingClassifier(random_state = 0,max_depth = 3,learning_rate = 0.01).fit(X_train,y_train)
'''
In[9]:
grbt = GradientBoostingClassifier(random_state = 0,max_depth = 3,n_estimators = 100,learning_rate = 0.1).fit(X_train,y_train)
In[10]:
print ('{}'.format(grbt.score(X_train,y_train)))
In[11]:
print ('{}'.format(grbt.score(X_test,y_test)))
In[12]:
'''
plot_feature_importances_cancer(grbt)
'''
In[13]:
'''
def plot_feature_importances_cancer(model):
n_features = cancer.data.shape()
plt.barh(range(n_features,model.feature_importance,align = 'center'))
plt.yticks(np.arange(n_features),cancer.feature_names)
plt.xlabel('Features importance')
plt.ylabel('Feature')
'''
In[14]:
n_features = cancer.data.shape[1]
plt.barh(range(n_features),grbt.feature_importances_,align = 'center')
plt.yticks(np.arange(n_features),cancer.feature_names)
plt.xlabel('Features importance')
plt.ylabel('Feature')
In[ ]:
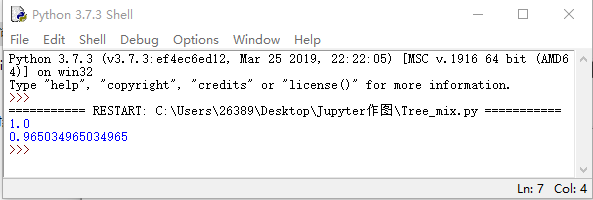
grbt = GradientBoostingClassifier(random_state = 0,max_depth = 1,n_estimators = 1000000,learning_rate = 0.1).fit(X_train,y_train)跑这波代码的时候,笔记本的风扇声音嗡嗡响,看来干这行很烧资源,浅尝辄止,🐸,处理好我的uC方向就好了,深入的没啥兴趣