

堆排序是很妙的一种非稳定排序算法,在数据量较大时,优势能够得到凸显,同时,有二叉树的形式却没有二叉树的气质🤣,可以体验一把!
数据结构的复习,到今天(我写这篇的时间)就结束了😀,或许有人会疑问,为何只到第十章?因为后面的暂时不用(之前辅修也没上)[顺带一提,当年辅修上数据结构的是计科院的孙辉老师,那叫一个严,差点跪了🤣]
- 严蔚敏(清华大学)C语言版+习题集(强推)
- 开发环境使用Visual Studio 2019 C
堆排序:
- 什么是堆
- 如何“筛选堆”
- 如何建立堆
- 如何堆排序
1.堆的定义:
严格来说分为两种,根据线性存储关系,当采用二叉树形式表示就是:
1.2小顶堆:父节点值不大于子节点
此处使用大顶堆做说明、编码(因为原书用小顶堆介绍,大顶堆编码🙃),大顶堆编码是有原因的,后面体会到排序时就能理解了!
2.何为筛选
就是将一个无序序列(也有歧义),按照二叉树的模式(顺序线性存储架构)生成一个堆(取小介绍),这样表示的原因是很有意思的!
假设一个无序序列构成的二叉树(顺序编码),根据从[length/2]节点到根节点的逐渐变化,使其成为一个“堆”
实际上这有点不靠谱🤣,通常是假设一个已建立好的大顶堆,将根节点值和最后一个节点值互换(同时被互换的节点值除外),则根据最大孩子路径原则,根据路径依次替换,可以实现重建堆,而不破坏原有的架构
下面这篇博文写的非常好,建议看看
https://www.zhihu.com/tardis/sogou/art/45725214
void HeapAdjust(HeapType& H, int s, int m)
{
OrderRedType rc;
rc = H.r[s];
for (int j = 2 * s; j <= m; j *= 2)
{
if (j < m && LT(H.r[j].key, H.r[j + 1].key))
{
j++;
}
if (!LT(rc.key, H.r[j].key))
break;
H.r[s] = H.r[j];
s = j;
}
H.r[s] = rc;
}
3.如何建立堆
本质就是,仔细想想,完全可以理解,就是一个从[length/2]节点到根节点的筛选过程
- 起点为[length/2]并逐渐递减
- 对每个序列集使用筛选算法
- 直到最后的根节点

看起来有点难理解,实际上,只要对二叉树足够熟悉,加上数组的存储结构,以及所谓“筛选”的具体操作,就能理解
PS:在上述程序里面,为何起点s的递增是以2倍,只要你熟悉二叉树存储架构以及父节点和左右子节点的关系(部分二叉树性质[完全二叉树衍生]),就能理解
4.排序(堆)
本质就是取得根节点值,再对整个除去了(实际上是和最后一个元素替换,在后续的处理中,不包括在内)根节点值的新树进行筛选[范围为1-(i-1)],其中i为:
H.length的逐渐递减(因为最后一个就是替换了的最大值堆顶元素)
据此逐步向下推进,就可以实现堆排序(整个堆按照有序组成)
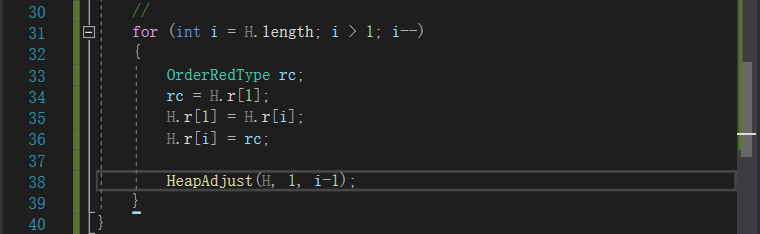
void HeapSort(HeapType& H)
{
for (int i = H.length / 2; i > 0; i--)
{
HeapAdjust(H,i,H.length);
}
//
for (int i = H.length; i > 1; i--)
{
OrderRedType rc;
rc = H.r[1];
H.r[1] = H.r[i];
H.r[i] = rc;
HeapAdjust(H, 1, i-1);
}
}
写在最后:
至此,数据结构的复习基本完成(除去没看的,当然,这部分也没要求,毕竟不是真的钻研底层,只是学习一下数据架构和基本算法)
关于这次复习,有以下几点:
- 时间太快,不到两个礼拜
- 几乎天天在看,这就比较刺激了,头疼
- 基本内容和算法都是预料之内,情理之中,因为学过🐸
这次学的也算比较深入吧,基本概念和算法几乎全部考究和部分改良了一遍,还有极少部分不能完全理解,留待后续吧