

我想,现在我大概有点体会到,为什么说深度学习是传说中的炼丹了,虽然刚刚试了下神经网络基本模型,额,已经深有体会了,MDZZ,差点把CPU玩烧了🐸
display(mglearn.plots.plot_logistic_regression_graph())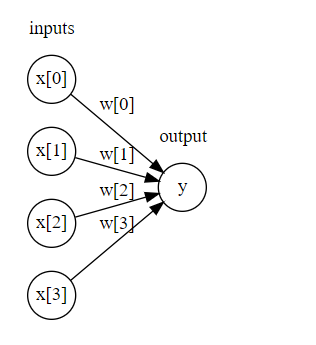
从最简单的无Hidden-layer,到单隐层,再到双隐层,复杂度增加的同时,消耗资源也在上升,然而,并没有体会到啥好玩的地方,并且跑同样的数据集,耗费时间增加了不少!同时参数对网络的影响太大了,玄学一样
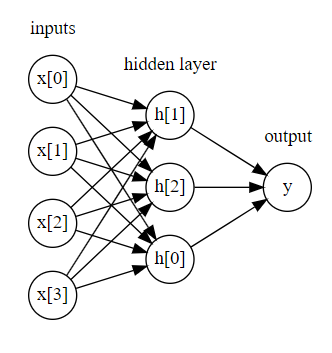
display(mglearn.plots.plot_single_hidden_layer_graph())
display(mglearn.plots.plot_two_hidden_layer_graph())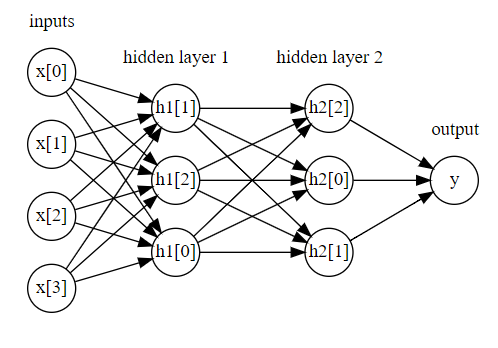
刚才说了,网络的复杂性增加的同时,资源消耗也在上升,而且可能是大于线性表征的上升,并且,复杂的模型未必就比简单的模型拥有更高的泛化精度,刚说了,参数的影响太大,或者说是太敏感,就拿双隐层和三隐层而言
mlp = MLPClassifier(solver = 'lbfgs',random_state = 0,activation = 'tanh',hidden_layer_sizes = [10,100,100]).fit(X_train,y_train)mlp = MLPClassifier(solver = 'lbfgs',random_state = 0,activation = 'tanh',hidden_layer_sizes = [10,10]).fit(X_train,y_train)设定三隐层的每个隐层的神经元数目如上所示,双隐层亦如上,分别为下述指标
[10,100,100][10,10]
采用tanh作为神经元激活函数,relu暂未用到,两种模型在相同的训练集下的表现如下,图示为训练集上的划分边界可视化
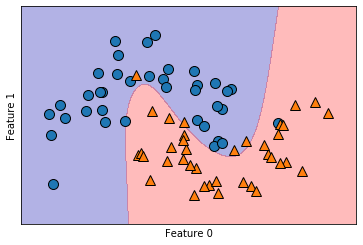
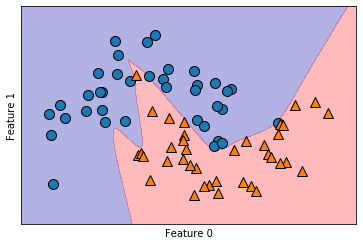
实际上,就训练集划分而言,双隐层网络的精度明显更高,而三隐层还存在错误划分现象,其在训练集和测试集上的精度分别如下

print ('{}'.format(mlp.score(X_train,y_train)))
print ('{}'.format(mlp.score(X_test,y_test)))尽管三层网络的训练集上的表现只有0.93,但是其测试集上的性能(泛化性能)却高达0.96,相对的,双层隐层网络虽然训练集表现较好,但是泛化性能却只有0.84,显然三层网络的性能更好,至于two_layer其训练集的0.98,很明显,产生了过拟合问题
mlp = MLPClassifier(solver = 'lbfgs',random_state = 0,activation = 'tanh',hidden_layer_sizes = [100,100,100]).fit(X_train,y_train)改动三隐层网络的首层神经元数目,再次训练模型,并利用模型预测


该模型的训练集拟合度为1.0,可以说是完美,然而泛化性能只有0.88,过拟合,因为模型需要预测的是训练集里面所没有的数据的输出,泛化性能很重要(训练集精度也要保证,两者应当兼顾)