
输入样本的属性个数唯一,输出个数唯一,简而言之可以在平面坐标系上构建点集,通常而言这样的点集可以用线性模型进行拟合
y = a*x + b设定以y表示输出值,x表示输入值,对于D={(x1,y1),(x2,y2),(x3,y3)……,(xn,yn)},作为样例集,输入输出都是一维空间上的数,对于构建线性模型而言,二者无需通过复杂的矩阵建立联系,训练目的在于勾画出一条直线,标准,也就是确定模型参数的标准(模型种类已经选定)
最小均方误差(MMSE),即利用构建模型对所有训练集的样本进行预测,|y_r-y_p|,对于D={(),(),()}的所有x进行,预测值为y_p,而y_r为真实值,取其差值平方,求和,再除以D样例集总数,选定一个会使得MSE最小的参数a和b,实际上由于STEP的步进,a和b只是在STEP内满足MSE最小
a和b的初始取值,以及其变化的规律等,都有严格的数学推论
重要的是,此前的一些比赛中的单一传感器数据分析,2019年的电赛题目,纸张测量问题,实际上可以理解为一个机器学习的实践类题目,就是单一传感器的数据分析预测,隶属于机器学习里面的,监督学习,线性模型并且是回归类型模型(暂且定义为回归,因为纸张数只能取整数,预测值也需要取整,但并不影响回归模型的使用)
测定不同纸张数对应的传感器值(容值),D={(x0,0),(x1,1),(x2,2),(x3,3),……(x100,100)},采集数据,保存记录.csv文件,利用Python进行模型拟合,求解
y = A*x + B 数据的预处理问题
一般原始的输入数据需要进行预处理,像归一化,去均值,去方差等,将处理后的数据用作输入值,输出值不变化,进行建模
pre_process = preprocessing.MinMaxScaler()
x = pre_process.fit_transform(source_set)对于IDE,建模完成后的模型视为其实例化的结构模型,但是一般比赛不允许使用电脑辅助(树莓派也属于),因此,需要将建模完成的模型参数输出,用于移植进入uC控制器
print (Line_Reg.coef_)
print (Line_Reg.intercept_)y_ = Line_Reg.coef_[0] * x_ + Line_Reg.intercept_[0]以浮点数植入控制器,使用时根据实际值四舍五入取整
然而,实际情况咋样?
如果该传感器的线性关系比较明显,那么通过建模是完全可行的,并且,应当可以达到较高的准确度(精度测量需要用设计的模型进行现场测试)
一种情况,如果该传感器的敏感度较高,那么一张纸的容值变换足够大,甚至连建模都不需要(在要求测试的纸张较小的情况下,如果是1000,10000,100000等量级,逐一测量,标定区分空间显然不现实),因此建模预测才是正规的方式
为了保证精度,通常取值不能太小,取定0、1、……、100张纸的容值作为训练集,(x,y),x表示容值,y表示对应的纸张数,对此训练集建模
将建立好的模型进行测试,取定[0:100]整数值作为验证集,测定其验证误差(误差太大可能需要修正,如果非常小,甚至是没有,则该模型可进一步测试),这里使用多次测量,排除偶然误差
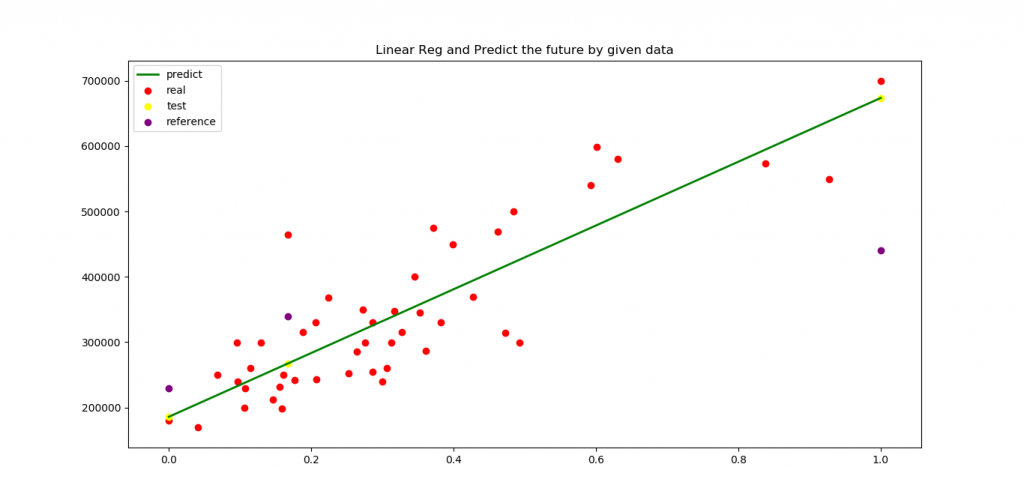
plot.scatter(x_set,y_predict,color = 'yellow',label = 'test')
plot.scatter(x_set,y_real,color = 'purple',label = 'reference')测试集测试包括,随机选取D={(x101,101),(x201,201),(x301,301),(x401,401),(x501501)….,(x1001,1001)},这里举例而已,不一定非得这些值,验证模型的测准率如何,如果完全测准(多次测量),则模型可用,如果差异较小(可以修正),模型可用,如果误差太大(无法修缮),则模型不可用,一般情况下,传感器的线性度较高时,应当没问题
传感器的datasheet
注意其线性度测量范围即可,不要超量程测量,因为非线性数据需要其它的模型预测,复杂度可能较高

print (Line_Reg.coef_)
print (Line_Reg.intercept_)